섹션 1. 자료구조(Data Structure)
배열과 리스트 그리고 벡터
기존 자료구조인 배열과 리스트는 비슷한 점도 많지만 다른점도 많다.
배열
배열은 메모리의 연속 공간에 값이 채워져 있는 형태의 자료구조
배열의 값은 인덱스를 통해 참조, 선언한 자료형의 값만 저장 가능
배열의 특징
- 인덱스를 사용하여 값에 바로 접근 가능 ex) A[3]
- 새로운 값을 삽입하거나 특정 인덱스에 있는 값을 삭제하기 어려움, 해당 인덱스 주변에 있는 값을 이동시키는 과정이 필요 ex) A[3] 값 추가시 A[4], A[5]를 오른쪽으로 한칸씩 이동 후 삽입
- 배열의 크기는 선언할때 지정할수 있으며, 한번 선언하면 크기를 늘리거나 줄일 수 없다.
- 구조가 간단함으로 코딩 테스트에서 많이 사용
리스트
리스트는 값과 포인터를 묶는 노드라는 것을 포인터로 연결한 자료구조
Tip) 노드는 컴퓨터 과학에서 값, 포인터를 쌍으로 갖는 기초 단위
리스트의 특징
- 인덱스가 없으므로 값에 접근하려면 Head 포인터부터 순서대로 접근, 배열에 비해서 접근하는 속도가 느림
- 포인터로 연결되어 있으므로 데이터를 삽입하거나 삭제하는 연산 속도가 빠름
- 선언할때 크기를 별도로 지정하지 않아도 된다. 리스트의 크기는 정해져 있지 않으며, 크기가 변하기 쉬운 데이터를 다룰때 적절함
- 포인터를 저장할 공간이 필요함으로 배열보다 구조가 복잡
벡터
기존의 배열과 같은 특징을 가지면서 배열의 단점을 보완한 동적 배열의 형태
벡터의 특징
- 동적으로 원소를 추가할 수 있다. 즉, 크기가 자동으로 늘어난다
- 맨 마지막 위치에 데이터를 삽입하거나 삭제할 때는 문제가 없지만 중간 데이터의 삽입 삭제는 배열과 같은 메커니즘
- 배열과 마찬가지로 인덱스를 이용하여 각 데이터를 직접 접근
개발자가 사용하기 편리하고 쉽기 떄문에 코딩 테스트에서 굉장히 많이 사용한다.

구간 합
합 배열을 이용하여 시간 복잡도를 더 줄이기 위해 사용하는 특수한 목적의 알고리즘
합 배열 S의 정의
S[i] = A[0] + A[1] + … A[i - 1] + A[i]
즉 A[0]부터 A[i]까지의 합
합 배열 S를 만드는 공식
S[i] = S[i - 1] + A[i]
구간 i에서 j까지 구간 합을 구하는 구간 합을 구하는 공식
S[j] - S[i - 1]
ex) 투 포인터 실전 문제 좋은 수 구하기 (백준 1253)
- 문제 분석
- N의 개수가 최대 2000
- 좋은 수 하나를 찾는 알고리즘의 시간 복잡도는 최소 O(nlogn)
- 정렬, 투 포인터 알고리즘 사용
- 정렬된 데이터에서 자기 자신을 좋은 수 만들기에 포함하면 안된다.
- 문제에 주어진 다른 두 수의 합으로 표현되는…. 을보고 투 포인터를 추측
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<int> a(n, 0);
for (int i = 0; i < n; i++) {
cin >> a[i];
}
sort(a.begin(), a.end());
int result = 0;
for (int k = 0; k < n; k++) {
long find = a[k];
int start = 0;
int end = n - 1;
while (start < end) {
if (a[start] + a[end] == find) {
if (start != k && end != k) {
result++;
break;
}
else if (start == k) {
start++;
}
else if (end == k) {
end--;
}
}
else if(a[start] + a[end] < find){
start++;
}
else {
end--;
}
}
}
cout << result;
}
스택과 큐
스택과 큐는 배열에서 조금 더 발전한 형태로, 구조는 비슷하나 처리 방식이 다르다.
스택
스택은 삽입과 삭제 연산이 후입선출(Last in First out)로 이루어지는 구조
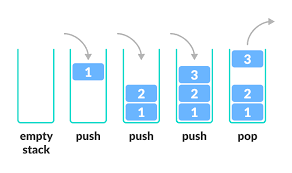
위치
top : 삽입과 삭제가 일어나는 위치
연산
push : top 위치에 새로운 데이터를 삽입하는 연산
pop : top 위치에 현재 있는 데이터를 삭제하고 확인하는 연산
top : top 위치에 현재 있는 데이터를 단순 확인하는 연산
스택은 깊이 우선 탐색(DFS : Depth First Search), 백트래킹 종류의 코딩 테스트에 효과적이다.
후입선출 개념은 재귀 함수 알고리즘 원리와 비슷하다.
큐
큐는 삽입과 삭제 연산이 선입선출로 이루어지는 자료구조
삽입과 삭제가 양방향에서 이루어진다.
값 추가는 큐의 back에서 이루어지고, 삭제는 큐의 front에서 이루어진다.
위치
back : 큐에서 가장 끝 데이터를 가리키는 영역
front : 큐에서 가장 앞의 데이터를 가리키는 영역
연산
push : back 부분에 새로운 데이터를 삽입하는 연산
pop : front 부분에 있는 데이터를 삭제하고 확인하는 연산
큐는 너비 우선 탐색(BFS : Breath First Search)에서 자주 이용
Tip) 우선 순위 큐
우선순위 큐(Priority queue)는 값이 들어간 순서와 상관없이 우선순위가 높은 데이터가 먼저 나오는 자료구조이다. 큐 설정에 따라 front에 항상 최대값 또는 최소값이 위치한다. 우선순위 큐는 일반적으로 힙(Heap)을 이용해 구현한다.